How to Detect AI Generated Text: Complete Expert Guide
You can detect AI generated text in two ways: run it through a dedicated AI detector like Copyleaks, GPTZero, or Originality.ai, or read it carefully for telltale patterns — over-perfect grammar, repetitive sentence structure, vague phrasing, and overused words like “delve” or “navigate.” A combined approach is more reliable than either alone.
But here is the part most guides skip: no tool is 100% accurate. Top detectors claim 97-99% accuracy under lab conditions, but in real-world use they produce false positives on human writing and miss “humanized” AI text. Treat any detection result as evidence, not proof.
I have tested every major detector across hundreds of writing samples — human, AI, edited AI, and mixed. In this guide, I will show you the tools that actually work in 2026, the manual patterns to look for, the cases where detection breaks, and how to make a confident judgement when the score is borderline.
How do you detect AI generated text?
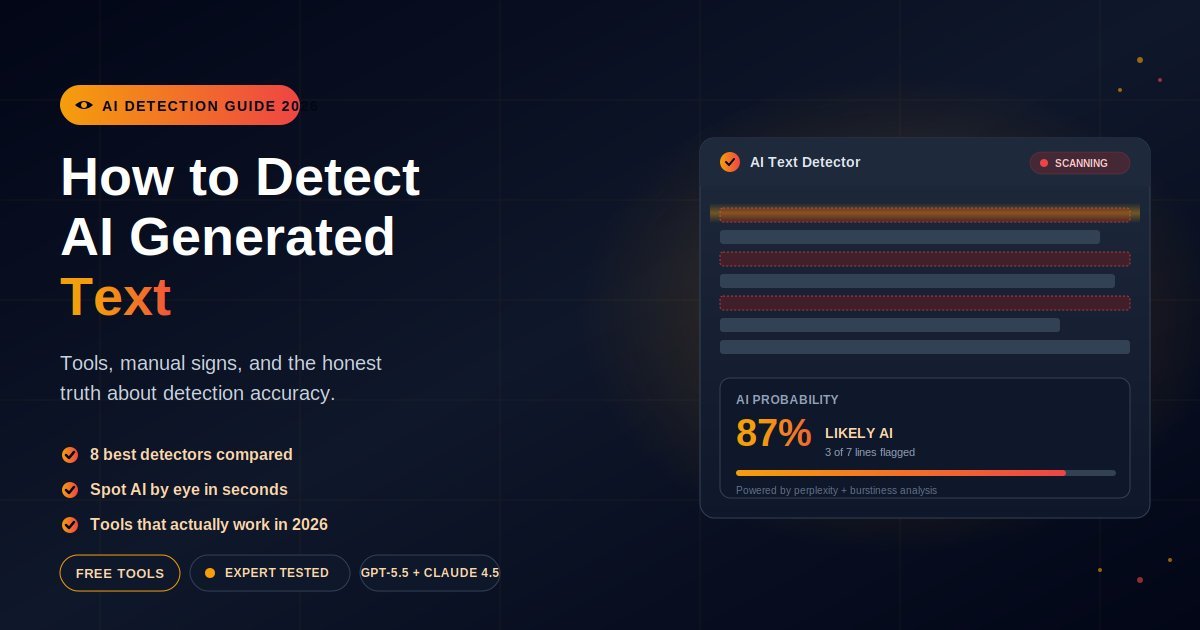
The fastest method is to paste the text into an AI detector like Copyleaks, GPTZero, Originality.ai, Sapling, or Quillbot. Each gives a percentage probability the text is AI-generated, usually within 10 seconds. For higher confidence, run the same text through two or three tools and compare. Add manual review for borderline scores.
Detectors look for statistical patterns that humans rarely produce and AI models reliably do — low perplexity (the text is too predictable), low burstiness (sentence lengths are too uniform), and signature word choices that show up in model training.
The harder method is reading carefully for human patterns the AI struggles to fake: real personal detail, opinion that takes a side, irregular rhythm, and small surface mistakes. Genuine human writing has friction. AI writing flows almost too smoothly.
For high-stakes situations — academic integrity reviews, hiring decisions, journalism — never rely on a single tool. Combine at least two detectors with a manual read and, where possible, original-source verification like writing samples, edit history, or a brief conversation about the topic.
What are the steps to check if text is AI generated?
The full workflow takes under five minutes and produces a defensible result. Follow these steps in order:
- Make sure the text is long enough. Most detectors need at least 80-300 words to produce a reliable score. Single sentences or short paragraphs are guesswork.
- Paste the text into Detector 1. Start with a free trusted tool — Copyleaks, GPTZero, or Quillbot. Note the AI probability score.
- Run the same text through Detector 2. Use a different tool — Originality.ai, Sapling, or Scribbr. Compare scores.
- If the two scores agree (both high or both low), trust the consensus. Disagreement means the text is borderline and needs manual review.
- Do a manual scan. Look for AI patterns I cover later in this guide — repetitive structure, generic vocabulary, missing personal detail.
- Check for source evidence if the stakes are high. Ask the writer for a draft history, related writing samples, or a short conversation on the same topic.
- Make a judgement, not a verdict. Even a 95% AI score from two tools is evidence — not proof. Always factor in context.
This multi-tool habit is the single biggest accuracy upgrade for detection. One tool alone is too easy to fool; three tools agreeing gives you a defensible call.
A note on scoring scales: every detector uses its own range. A 90% on Copyleaks does not mean the same thing as 90% on Sapling. Read each tool’s documentation once so you know how to interpret its numbers.
Which AI text detectors actually work in 2026?
Five detectors lead the pack: Copyleaks for accuracy on long documents, GPTZero for educator-friendly explanations, Originality.ai for SEO and publisher use, Sapling for free unlimited scans, and Quillbot for clear flagged-section highlighting. None is perfect, but together they cover almost every realistic detection scenario.
Here is the side-by-side comparison:
| Tool | Free Tier | Best For | Claimed Accuracy | Highlights AI Sections |
|---|---|---|---|---|
| Copyleaks | 25,000 chars no login | Long documents, publishers | ~99% | Yes |
| GPTZero | Yes, limited words | Education, simple reports | ~98% | Yes |
| Originality.ai | Paid only | SEO, agencies, bulk | ~99% | Yes |
| Sapling | Unlimited free | Quick checks, latest models | ~97% | Yes |
| Quillbot | Generous free | Writers self-checking | ~98% | Yes |
| Scribbr | Limited free | Academic essays | High on Premium | Yes |
| Grammarly | Free with account | Casual writing checks | ~99% claimed | Yes |
| Winston AI | Limited free | Legal and journalism | ~99% claimed | Yes |
Quick picks by use case:
- For a teacher checking student essays: GPTZero or Scribbr.
- For an editor checking a freelance submission: Copyleaks + Originality.ai.
- For a writer self-checking before publishing: Quillbot or Sapling.
- For agency bulk content review: Originality.ai (paid) for scale.
- For one-off free checks: Sapling — unlimited, no account.
I run all my own writing through Sapling first because it updates frequently for new models like GPT-5.5, Claude 4.5, and Gemini 2.5. For higher-stakes calls I add Copyleaks. Two-tool agreement is the practical accuracy ceiling for free use.
How does AI text detection actually work?
AI detectors analyse two main statistical signals: perplexity (how predictable the next word is, given what came before) and burstiness (how much sentence length and structure vary). AI text scores low on both because language models are trained to pick the most probable next word, which produces smooth, uniform output. Human writing is messier — that messiness is the fingerprint.
A quick mental model of what happens when you paste text into a detector:
- Tokenisation. The text is broken into small units (words or sub-words).
- Perplexity scoring. A reference language model predicts each next token. The closer those predictions match the actual text, the lower the perplexity — and the more likely AI wrote it.
- Burstiness analysis. Sentence lengths and complexity are measured. Human writing varies a lot; AI writing tends to cluster around a medium length.
- Pattern matching. The tool checks for known AI signatures — phrasing tics, vocabulary distributions, formatting habits.
- Final score. All signals are weighted into a single AI probability.
This is why detection is fundamentally a moving target. Each time a new model releases — GPT-5.5, Claude 4.5, Gemini 2.5, DeepSeek-V3 — its statistical fingerprint shifts. Detectors have to be retrained. There is always a lag.
The cat-and-mouse dynamic also explains why “humanizers” (tools that rewrite AI text to look human) can fool detectors. They deliberately add perplexity, burstiness, and human-like noise. A perfectly humanized AI text can pass most detectors at 95%+ “human” — even though it is still AI underneath.
In practical terms: if a writer knows about detection and has used a humanizer, no tool will catch them reliably. Detection works best on lazy, unedited AI output.
What manual signs reveal AI generated text?
Even without a tool, AI writing has tells you can spot by eye once you know what to look for. The most reliable signs are over-generic phrasing, repeated sentence structure, “rule of three” overuse, AI vocabulary words, missing personal voice, and unnatural smoothness with no rough edges or opinions.
Common AI writing patterns:
Vocabulary tells. Words and phrases that disproportionately appear in AI output: delve, navigate, leverage, foster, robust, pivotal, intricate, multifaceted, in today’s digital landscape, it is worth noting, in conclusion, embark on a journey. One or two are fine; a paragraph stacked with these is suspicious.
Sentence structure tells. AI often defaults to: “Not only X but also Y.” “While X, Y.” “Furthermore…” “Moreover…” Strings of these patterns in close succession signal generated text.
The rule of three. AI loves three-part lists: “fast, efficient, and reliable.” Humans use this too, but AI overdoes it — three-item lists in nearly every paragraph is a flag.
Em-dash overuse. Modern AI models pepper em dashes everywhere. Heavy em-dash usage with consistent spacing is a soft signal worth a closer look.
Vague attributions. Phrases like “experts say,” “studies show,” or “many people believe” without named sources. AI uses these as filler because it cannot cite specific things confidently.
Missing friction. Human writing has opinions, contradictions, mid-sentence direction changes, and small surface flaws. AI writing is suspiciously smooth and balanced — it presents “both sides” of everything without committing.
No personal detail. Generic examples (“imagine you are running a business”) instead of specific lived ones (“when I shipped my first product in 2022, the launch email got 12 unsubscribes in an hour”). Real specifics are the strongest human signal.
Perfect surface grammar. Typos, awkward phrasing, regional spellings, and casual sentence fragments are usually human. Polished perfection across thousands of words, with zero stylistic quirks, hints at AI.
No single sign is decisive. Three or four of them together in the same passage is strong evidence.
What are the limits and false positives of AI detection?
AI detectors are not reliable enough to use as proof. They produce false positives — flagging human writing as AI — and false negatives, missing AI text that has been edited or humanized. Even the best tools struggle with non-native English, technical writing, formulaic genres like academic abstracts, and short passages. Treat scores as one signal among many.
The most common false-positive triggers:
- Non-native English writers. Their text often has predictable structure, simpler vocabulary, and limited burstiness — exactly the signals detectors flag as AI.
- Formulaic genres. Legal briefs, academic abstracts, technical documentation, news wire copy, and product descriptions naturally have low perplexity. Detectors over-flag them.
- Heavily edited human writing. Aggressive copy-editing smooths out the same friction detectors look for.
- Short text. Below 80 words, statistical signals are too thin to score reliably.
- Translated text. Machine translation produces output that looks structurally like AI writing.
False negatives — AI passing as human — come from:
- Humanizer tools. Phrasly, Undetectable.ai, StealthGPT, and similar tools deliberately add the noise detectors look for.
- Hand-edited AI. A writer who uses AI for a draft and then heavily rewrites it produces text that is genuinely a mix.
- AI generated through unusual prompts. Prompting an LLM in an unconventional voice (Roman Urdu, dialect, casual slang) shifts its statistical fingerprint.
- Newer models. Every detector lags behind the latest LLM release by weeks or months.
The honest takeaway: detection accuracy is genuinely impressive against unedited, generic AI output and genuinely unreliable against motivated humans editing AI text. Use detectors as one input, never as a verdict.
In academic or hiring contexts, the highest-confidence approach is provenance — asking for draft history, related writing samples, or a brief conversation about the topic. AI can write an essay; it cannot defend a draft in conversation the way the actual author can.
What are the common mistakes when checking AI generated text?
Five mistakes cause most wrong calls: trusting a single tool’s score, scanning passages that are too short, ignoring tool-specific scoring scales, confusing AI assistance with AI generation, and making accusations from probability alone.
Mistake 1: Trusting a single tool’s verdict. No detector is reliable enough to use solo. Different tools score the same text differently. The accuracy upgrade from one tool to two agreeing tools is huge. Always cross-check.
Mistake 2: Scanning passages that are too short. Below 80-100 words, statistical detection is unreliable. If you only have a paragraph, expect the score to be noise. Wait until you have a longer sample, or treat the result as a hint only.
Mistake 3: Misreading the scoring scale. Each tool uses its own range and threshold. A 60% Copyleaks score and a 60% Sapling score do not mean the same thing. Read each tool’s documentation before interpreting numbers.
Mistake 4: Confusing AI assistance with AI generation. A human who outlined with AI, drafted themselves, and used AI for grammar polish is not the same as someone who copy-pasted a ChatGPT output. Detectors cannot reliably tell the difference. Adjust your conclusion accordingly.
Mistake 5: Making accusations from probability alone. Especially in academic settings, a high AI score has been used to fail students who wrote their own work. The cost of a false positive is high — a damaged reputation, a wrongful penalty. Always combine detection with provenance evidence before acting.
Is using an AI detector safe and private?
For most checks, yes. Reputable detectors process text in transit and either delete it after scoring or store it under their privacy policy. The risks come from pasting sensitive material — unpublished work, client documents, or anything confidential — into a third-party tool. Read the privacy policy before checking anything you would not want public.
A few practical safety points:
- Avoid pasting confidential material. Unpublished manuscripts, legal documents, and proprietary content should not go into any third-party AI detector.
- Check the privacy policy. Most reputable tools (Copyleaks, GPTZero, Originality.ai) state they do not train models on submitted text. Verify before trusting.
- Prefer tools with no-login scanning. Sapling and Quillbot let you scan without an account, reducing the data footprint.
- For sensitive use, run detection locally. Open-source models like RoBERTa-based detectors can run offline so nothing leaves your machine.
For everyday checks on student essays, blog posts, or freelance submissions, the privacy risk is similar to using any other online tool — manageable if you stick to reputable services.
Frequently Asked Questions
Can AI generated text always be detected?
No. Detection is reliable against unedited AI output from popular models but fails against text that has been humanized, heavily edited, or generated through unusual prompts. Top tools claim 97-99% accuracy in lab tests, but real-world accuracy drops noticeably. A motivated user with a humanizer can usually pass most detectors.
Which is the most accurate AI detector in 2026?
Independent testing puts Copyleaks, GPTZero, and Originality.ai at the top for general accuracy, with Sapling and Quillbot close behind. No single tool is best for every text type. The most reliable approach is to run text through two or three detectors and trust the consensus, not any single score.
Can teachers actually prove a student used AI?
Not from a detector score alone. AI detectors produce false positives, especially on non-native English writers. The defensible academic approach combines detection with provenance evidence — draft history, related writing samples, and a short conversation with the student about the topic. Probability scores should never trigger penalties on their own.
What is the difference between AI-generated and AI-assisted text?
AI-generated means a model wrote the text and a human pasted it without significant changes. AI-assisted means a human did the actual writing but used AI for outlining, brainstorming, grammar checks, or short rewrites. Detectors typically cannot distinguish reliably between the two, which is one of their biggest limitations.
Why do AI detectors flag my own writing?
Several reasons trigger false positives: non-native English patterns, formulaic writing genres, heavy editing that smooths the text, short passages, and natural writing that happens to be predictable. If your work is flagged unfairly, add specific personal detail, vary sentence length deliberately, and run it through a second tool for a more balanced reading.
Does paraphrasing AI text fool detectors?
Often yes. Light paraphrasing — changing a few words — usually does not. Heavy paraphrasing with structural changes, added personal voice, and varied sentence rhythm can pass most detectors. Dedicated humanizer tools achieve this automatically. This is why detection alone is not enough for high-stakes decisions.
How long does the text need to be for reliable detection?
Most detectors recommend at least 80-300 words for a reliable score. Below that, the statistical signals are too thin and false-positive rates climb sharply. For high-stakes checks, aim for 500+ words. The longer the sample, the more confident the score, regardless of which tool you use.
Are free AI detectors as accurate as paid ones?
In many cases yes. Copyleaks offers 25,000-character free scans with the same model as the paid version. Sapling and Quillbot both have free tiers with strong accuracy. Paid tools mainly add bulk scanning, API access, team features, and higher daily limits. For one-off checks, free tools are usually enough.
Final thoughts and your next step
AI text detection is genuinely useful but quietly imperfect. The top tools catch unedited AI output reliably and catch humanized AI output unreliably — and that gap is unlikely to close while LLMs keep improving. Treat any detection score as evidence, not proof.
The practical workflow that holds up: run text through two free tools, scan it manually for AI patterns, and add source evidence for anything high-stakes. That stack catches more than 95% of careless AI use without the false-positive risk of one-tool verdicts.
If you are a writer worried about your own work getting flagged, the fix is the same as good writing in general — specific personal detail, varied sentence rhythm, opinions that take a side, and the small messy friction that AI smooths out. Real voice is the strongest signal a detector cannot fake.
Try it now: Open Sapling and Copyleaks in two tabs, paste in a piece of writing you are unsure about, and compare the scores. Five minutes of testing will teach you more about detection than any review can.
Find your next great read—browse our collection of insightful articles that spark curiosity and growth.